Introduction
In my personal philosophy, I classify newly learned information into different tiers of truthness based on where it comes from.
Here's how it breaks down:
- Experienced it myself – The gold standard. If I’ve lived it, it’s as true as it gets.
- Experienced by someone I know – Second-hand truth, but still reliable if the source is trustworthy.
- Anecdotes – The wild west of truth. Entertaining, but take it with a grain of salt.
Now I’ve heard great things about reinforcement learning. The promise of having an agent that knows nothing about its environment, learn how to operate in it through trial and error seems almost too good to be true!
I find it to be a good model of how us humans operate. Think about it: on our 0th birthday, we’re plopped into this vast, confusing universe. Through detecting patterns, experimenting, and learning from the consequences of our actions, each of us eventually become experts at living our own lives. (Admittedly, some of us are better at it than others.)
I’ve already dabbled with training AIs in pre-built environments, like the classic "balance a stick on a moving box" scenario. You know the one:

But, being the skeptic that I am, I couldn’t help but wonder: Does RL really work, or did they just cherry-pick this one narrow task where it happens to perform well? To put RL to the test, I decided to build my own custom environment from scratch and train an AI to operate in it.
How to Build a Custom Environment So That It’s Ripe for Training
But wait… What are we building?
Let’s start by dreaming up an idea—a universe for our little AI to spend its life in. I’ve always loved world-building in books/movies, and now it’s time for me to create my own.
Okay, how about we build a robot arm? It’s a precursor to robots that can actually pick things up. To keep things simple, let’s make it a 2D bot with 2D limbs.
We can make it do many things, like drawing, catching, juggling, waving, punching etc.
Now, technically, we don’t have to stick to human constraints—like making sure the elbow can’t bend backward—but that would look… well, funky. I want to see human-like behavior emerge from this coded-up bot, so let’s keep it somewhat realistic.
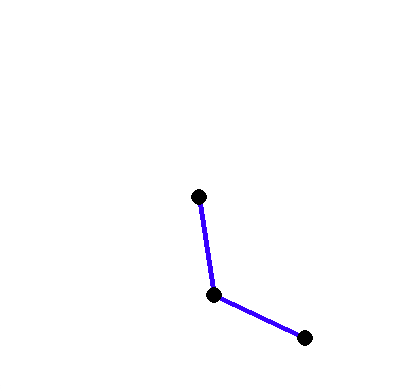
So I’m thinking it’s gonna have two motors: one on the shoulder and another on the elbow. We’re just gonna ignore the fact that my bot doesn’t have any hands.
(Tryna simplify the environment so the AI learns faster cuz I’m training on my MacBook Air 😭)

The goal of the environment will be simple: reach for the target. Sounds easy, right? But don’t forget—motor skills are hard. Even humans, with their billions of neurons, struggle to master them. Just watch a toddler trying to stand up for the first time.
Where Do We Start?
Sure, we could build the environment entirely from scratch. We could create an iteration loop, design a uniform interface to switch between manual and automated control, and then implement a learning algorithm from the ground up.
But, as mama always said, “Don’t reinvent the wheel.” Doing all that would be like someone asking you to make coffee, and instead of just brewing it, you fly to Ethiopia to pick the beans, dry them out, roast them, grind them… you get the idea.
So we’re gonna use some libraries to help us out.
My advice? Don’t think of the following libraries as the only way to do this. They’re just here to make our lives easier. Think of them as shortcuts—because who doesn’t love a good shortcut?
Tool 1: Gymnasium
Let’s start with what this tool can do for us.
Gymnasium provides a class that we can use to create custom worlds by implementing just a few functions. The best part? Once you’ve built your environment, it’s plug-and-play with a ton of RL algorithm libraries that support Gymnasium environments.
The class we’re interested in is called Env. It requires us to implement four main methods, and then we’re good to go. Here’s what it looks like:
class RobotArmEnv(gym.Env):
def __init__(self):
super().__init__()
def reset(self):
pass
def step(self, action):
return observation, reward, terminated, info
def render(self):
passTool 2: Stable Baselines 3
Next up, Stable Baselines 3. This library is a game-changer—it provides prebuilt learning algorithms that work seamlessly with Gymnasium environments. Exactly what we need to get our AI up and running without starting from scratch.
Here’s how simple it is to use Stable Baselines 3:
env = RobotArmEnv()
model = PPO('MlpPolicy', env, verbose=1) # ← Your one-line trainer
model.learn(total_timesteps=1_000_000)Yep, it’s that straightforward.
Right then, time to build out the robot’s world
Let’s start by creating the first joint: the shoulder. We’ll place it at the center of the screen, and it’ll be able to rotate a total of 90 degrees. Attached to the shoulder is the humerus bone (yes, we’re borrowing human anatomy here). At the end of the humerus, we’ve got the elbow joint, which connects to… well, where the hand should’ve been. The elbow can flex up to 180 degrees, giving our bot some serious range of motion.
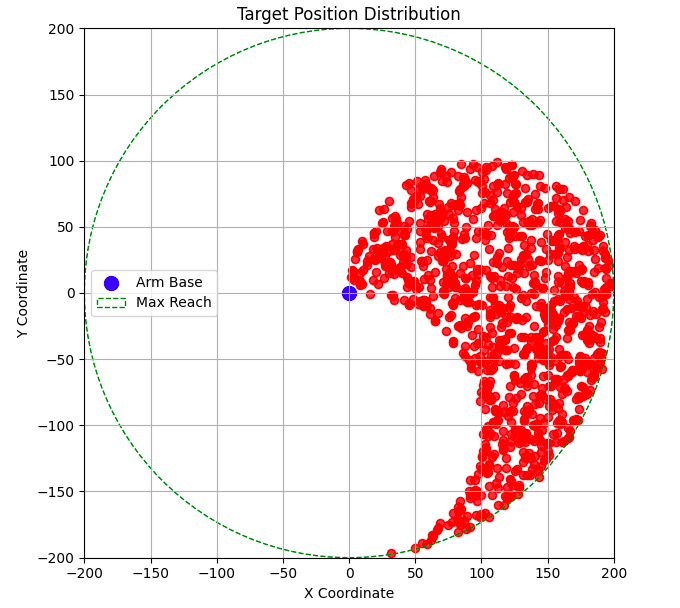
Now, let’s spawn a target at a random location within the robot’s reach. But first, we need to figure out where the robot can actually reach. Here’s a plot of the regions I think the robot might be able to access with this arm setup.
Okay, now let’s add the target to the robot arm environment:
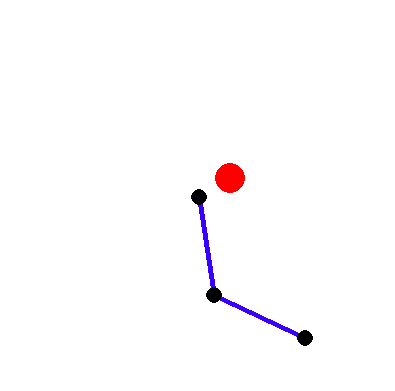
Nahh, something’s missing. It doesn’t have that robot vibe to it.
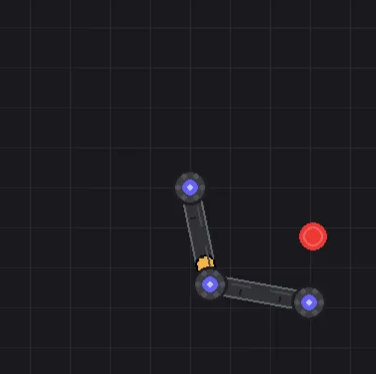
Much better.
Making it so we can interact with the environment
To test our newly created world, let’s make it interactive by allowing control through key presses.
Agent? Like CIA Agent?
Not exactly. Here, an agent is simply a decision-making AI that interacts with its environment by taking actions.
Let’s learn by examples:
In Fortnite:
The agent is the character you control. The environment is the game world—the map, other players, and everything else you interact with.

In a driving game:
The agent is your car. You (or the AI) can speed up, brake, or steer. The environment is the race track, other cars, and any obstacles.

Now in general:
The agent interacts with the environment by taking actions which in turn might affect the environment and then it receives observations of the affected state
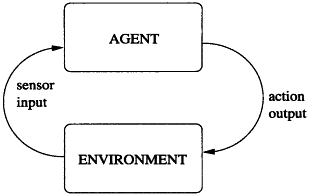
Observation
Ideally, you might want to let the robot see the environment in its entirety—raw pixels, full state, everything. But in practice, it’s much more efficient to extract and provide only the most important features. For example, you could teach an AI to play Pong by feeding it thousands of pixels and letting it figure out what to do. But here’s the catch: not only would the AI be learning how to play Pong, it’d also be learning how to see. And that’s a lot of extra work, making the process painfully slow.
Sure, this kind of end-to-end learning is possible, but to keep things simple, we’re going to give our agent hand-crafted features—specific pieces of information that we think will help it navigate the environment more effectively.
Here’s what our observation space looks like:
def _get_obs(self):
return np.array([
self.a1, # Shoulder angle
self.a2, # Elbow angle
*self.target, # Target position
self._calculate_distance() # Distance to target
])Let’s break this down:
-
Shoulder angle (
self.a1) and elbow angle (self.a2):These are like the robot’s sense of proprioception—the awareness of where its limbs are in space. Without this, the bot would have no idea how its arm is positioned.
-
Target position (
self.target):This is crucial because, well, you can’t move toward something if you don’t know where it is.
-
Distance to target (
self._calculate_distance()):Technically, the proprioception and target position should be enough. But to make things easier, we’re also telling the bot how far its hand is from the target. Think of it as giving the bot a little nudge in the right direction.
Actions
Just like when we controlled the bot manually using the keyboard, the AI will interact with the environment through the same set of actions:
- Increase shoulder angle
- Decrease shoulder angle
- Increase elbow angle
- Decrease elbow angle
We’ve also added one more action: no operation (doing nothing).
How do agents learn?
This is the heart of reinforcement learning. Unlike supervised learning, where you might explicitly tell an AI what action to take in a given state, reinforcement learning is all about letting the AI figure things out on its own. We guide the agent by rewarding good behavior and penalizing bad behavior, shaping its decisions over time.
The agent learns through a continuous loop:
- Observe: The agent gathers data from the environment.
- Act: The agent takes an action.
- Reward: The environment provides feedback (a reward or penalty) based on the action.
- Learn: The agent updates its policy to improve future decisions.
This loop is the backbone of reinforcement learning.
Here is the reward function I used to guide to robot arm:
reward = (
distance_reduction * 5.0 + # Encourage moving closer
proximity_reward * 0.5 + # Incentivize proximity
success_bonus - # Big reward for success
time_penalty - # Discourage slow solutions
action_penalty # Discourage unnecessary movements
)Different Algorithms
While the core idea of reinforcement learning is simple—maximize rewards—there are many different algorithms to achieve this. Each has its strengths and trade-offs and honestly, they deserve their own deep dive. Maybe that’s for a future blog. For the curious, I used PPO, mostly because Reddit, YouTube, and the broader RL community kept hyping it up.
Let the Training Runs Begin
You’d think the hard part would be setting everything up—creating the environment, setting up the training loop, and all that. But no, by far the hardest part was waiting.
Before diving into this robotic arm project, I messed around with a simple snake environment. That little guy mastered the game in about 10 minutes.
But this robotic arm? Oh no. This one takes its sweet, sweet time.
Here’s one of the earlier versions:
Remember the reward function I showed you earlier? Yeah, that’s the final version I came up with after training for 2 million steps. Initially, I had a much simpler reward function: the bot only got a reward when it actually hit the target. Sounds logical, right? But as it turns out, that’s not enough.
Enter reward shaping: the art of designing rewards that guide the agent toward desired behavior. Instead of waiting for the bot to randomly stumble upon success, we nudge it in the right direction by rewarding smaller milestones—like moving closer to the target or reducing unnecessary movements.
Instead of starting over, I kept the same model and tweaked the reward function after 2 million steps. I was hoping some of the training would carry over. Spoiler: it did.
As the model trained, I kept an eye on two key metrics: mean episode length and mean total reward. The episode length dropped from 200 (the maximum steps per episode) to around 70, meaning the bot was reaching the target faster. The mean reward also crept up, albeit slowly:
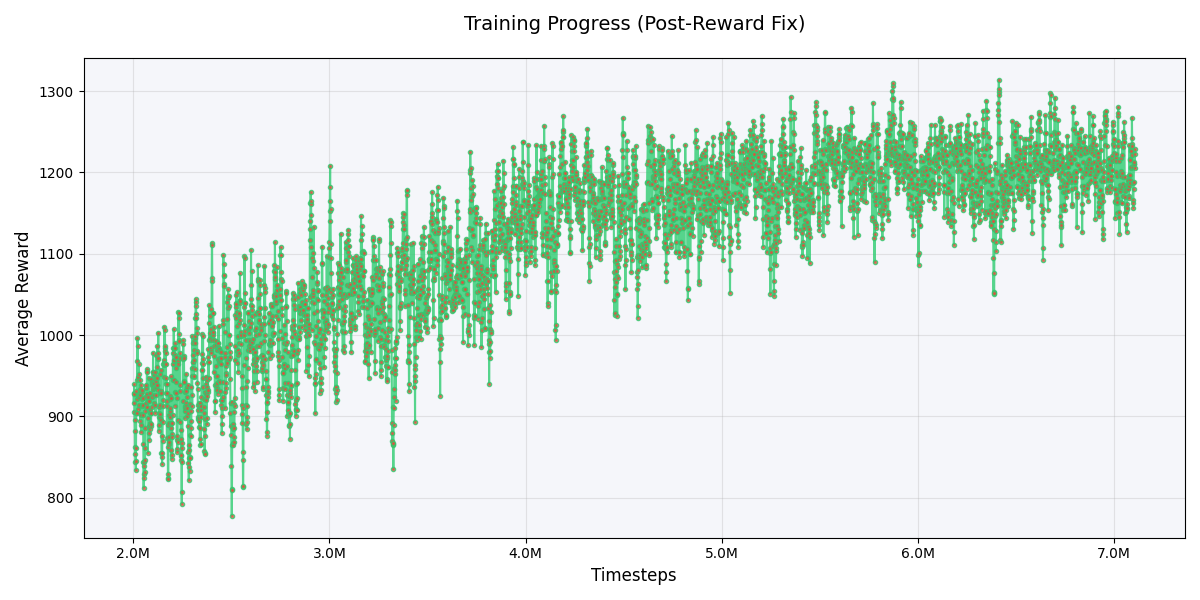
Watching Your AI Play
They grow up so fast 🥲:
After 7,000,000 steps (and about 4 hours of training), our little AI has gone from shaking nervously to gracefully reaching for its target.
Conclusion
Turns out, reinforcement learning isn’t just a made-up gimmick after all. It actually works! (At least, it worked for this very simple environment that I threw together.)
But here’s a thought: my bot had to go through around 100,000 games to get to this point. Meanwhile, I bet a 10-year-old kid could learn to hit the target with their hand after playing with the controls for, like, 10 games.
So, why do humans learn so much faster? One theory is that we rely on prior knowledge—our understanding of how the world works. We don’t start from scratch every time we learn something new. Instead, we build on what we already know, which gives us a massive head start.
Try It Yourself
Take this platformer, for example.

It feels pretty obvious what you have to do, right? Jump on the platforms, avoid the flytrap, and reach the flag. Now, imagine I flipped the game upside down. A little more difficult, but still manageable. Okay, what if I switched things up so the mushroom looks like the turtle and the turtle looks like the mushroom? Confusing, right? Now, what if I made everything completely indiscernible? Suddenly, the task becomes much harder.

I encourage you to try this platformer game where you can’t rely on your prior knowledge of the world:
After playing it, I empathize with my agents a lot more.
What’s Next?
If you’re inspired to tinker with this project yourself, here’s the GitHub repo:
And if you’re new to reinforcement learning, I highly recommend checking out OpenAI’s Spinning Up guide:
Room for Improvement
I’m fully aware that this isn’t the most accurate simulation of a robotic arm. To make it more realistic, we could add gravity, friction, and momentum—because, well, physics is a thing. 😅