Introduction
Breathe. Ponder this question:
What is thinking?
Your brain just did something—maybe:
“What is thinking? What’s he talking about? It’s… what your brain does, dummy. Wait, is this a trick? Ah, my thought’s are answering the question aren’t they.”
That internal monologue you just had? That’s called Chain-of-Thought (CoT). This is why we have good things. The weather’s a little too toasty? Turn on the AC—a product of centuries of nested CoT: inventing electricity, thermodynamics, circuitry, and finally, a machine that blows cold air.
Traditionally, LLMs learned Chain-of-Thought (CoT) in two ways:
- Getting Reasoning Traces from Training Data: From all the data used to train an LLM—internet content, books, Wikipedia, code—it detects patterns in how people structure arguments. For example it reads this part from a twitter argument: “No, you’re wrong about Theory A because it relies on Statement B being true, but I don’t think that’s the case.” The LLM learns to replicate these reasoning patterns in new contexts.
- Post-Training Fine-Tuning: After initial training, LLM companies can pay experts to painstakingly write step-by-step guides for specific problem types. These guides are then used to fine-tune the model’s CoT ability. For example, an expert might write down:
Q: Solve 2x + 3 = 4
<think>
1. Subtract 3 from both sides: 2x = 1
2. Divide by 2: x = 1/2
3. Verify: 2*(1/2) + 3 = 4 ✅
</think>
A: x = 1/2As I read the DeepSeek research paper, I realized we’ve entered a new, better paradigm: Forget hand-holding AI with curated reasoning steps. Gone are the days of manually guiding the large language model to use cognitive strategies like backtracking, self-verifying, finding analogies, or trying different angles.
The new approach? Let models loose in domains with objective truths—math, coding, physics—where answers are unambiguously right or wrong. And the model will learn how to think by itself. How?
Reinforcement Learning (RL):
- Step 1: Pose questions with clear answers (e.g., “Solve this equation”).
- Step 2: Let the model vomit up random reasoning paths (yes, even chaotic ones).
- Step 3: Reward paths that end up resulting in the correct answer. Repeat.
(It’ll have to learn how to think to consistently reach the correct answer)
This new RL-based training of LLMs’ CoTs aligns with Rich Sutton’s Bitter Lesson: AI learns best when we let it learn on its own, rather than trying to embed human knowledge into it.
With this technique, DeepSeek’s RL-trained model taught itself to backtrack, self-correct, and find analogies—no babysitting.

Now that I’ve put you up to speed on the crux of DeepSeek’s innovation, this blog is about the 5 ideas I came up with as I read the research paper.
Idea 1: Objective Subjects Are Ripe Playgrounds for Learning
There are fields of study where you have objective answers for questions—mathematics, coding, physics. In such scenarios, you can formulate questions and corresponding answers, then leave the LLM (or human!) to try and reach answers from questions. In doing so, they’ll understand the underlying structure that leads to the right answer.

What I’m hypothesizing is that these playgrounds allow someone to detect the underlying patterns and structure of those realities. If a person has a lot of time and tries many questions, they’ll also start to see a way of thinking that unifies maths, coding, and other objective domains. Logic is one such underlying structure.
Another pattern you learn in these domains is that there are often various “correct” ways to do the same thing, but some methods are faster or more efficient. An example is bubble sort vs. merge sort, or using numerical approximation to solve linear equations instead of algebraic manipulation.
Another pattern observable in both physics and finance is the critical role of time. Just as you can’t travel from Earth to Mars in less than three minutes (constrained by the speed of light), in finance you can utilize compound interest to earn a lot of money over years. Making a million dollars in a day might be hard, but put $35k in an interest account (7%), wait 50 years, and voilà—your million dollars.
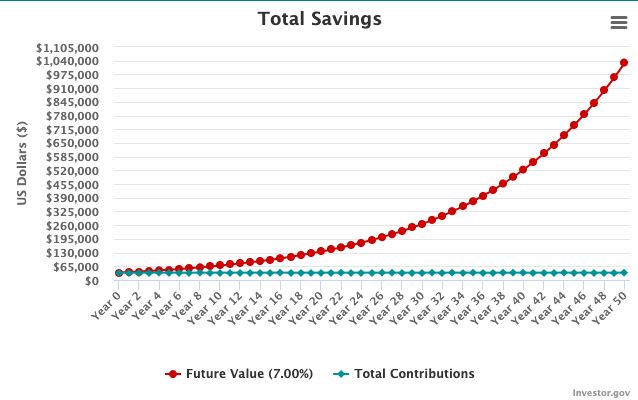
An observation: many technical people I meet are capable of having logical or reasonable conversations. (Ofc, they can choose to use these skills or not in their daily lives.) The same isn’t necessarily true for non-technical people. The reason? Technical folks, by necessity, had to learn cognitive strategies to survive in realities like math or coding—where failure is unambiguous.
Think pineapple belongs on pizza? Prefer socialism over capitalism? Believe Nation A is morally right? Cool—subjective debates are humanity’s playground.
But try building a rocket with propellers instead of jets? Sorry, physics doesn’t care about your feelings. You’ll fail, just like an AI that can’t reason in objective domains.
This idea extends to entrepreneurs. Running a business means interacting with the market—an objective reality. The principle of value exchange, diligence, avoiding scams—these aren’t abstract ideas. They’re survival strategies you must internalize to succeed.
Idea 2: Math and Coding Are Two Playgrounds That Are Isolated and Self-Contained
Math and coding are two independent “realities” that can be explored in isolation, without relying on a broader context. They are self-contained modules where all you need are the rules of math and perhaps a compiler for programming. Unlike business, they provide quick and rapid feedback, creating a fertile envrionment for learning patterns.


Bill Gates was young af, but he spent years immersed in the “computer” reality—and built Microsoft. Similarly, in this PBS episode, we see that Newton worked 7 days a week, 18 hours a day. That much time with pen and paper? Of course he saw patterns—and invented calculus.
So you really don’t have any excuse to be dumb. Go out there, get a pen and paper or get a computer and start playing with maths/programming and learn insights about life!
One tip: When you’re exploring these realities give yourself space to see patterns by keeping an open mind/being truthful to yourself that you don’t have all the insights that can possibly be attained. Take your time, too.
In writing this blog, I attempted a highschool math exam and I noticed that I was blazing through the questions, I’d see that I got the correct answer and would move to the next question but perhaps a better way is for me to really ponder about every step I took. Why did I take the approach that I took? What other ways could there be of solving the problem. How can I relate this problem with real life?
Idea 3: Model Distillation as an Analogy for Humans Learning from Experts

When DeepSeek tried to teach a small model to learn purely by RL, it performed worse than when a bigger smarter model taught it.
And the basic idea is that just like how it is in models, the same might apply for humans. It might be the case that on your own interacting with realities you might not be able to find sophisticated reasoning patterns, but you can learn them from others (other smarter people or humanity in its entireity). We do this by reading books, watching lectures, etc

Other people often detect better patterns about us than we do - This is an example of how we can learn from other people’s ideas.
In a letter to Robert Hooke in 1675, Isaac Newton made his most famous statement: “If I have seen further it is by standing on the shoulders of Giants”.
Idea 4: Move 37 for Thinking

Just like how “Move 37”—the infamous play in AlphaGo’s match against Lee Sedol, the world’s best Go player—shocked experts with its unexpected brilliance, training LLMs to think via self-learned chains of thought could unlock problem-solving strategies we’ve never imagined.
<Spoiler Alert for Arrival>
Y’know how in Arrival, the protagonist learns the alien language and gains a new way of thinking (across time—obviously impossible, but a cool metaphor for unlocking new chains of thought).
</Spoiler Alert>
Another analogy: learning a new language reshapes how you see the world. After taking French, I’ll never look at cheese the same way.
I remember grinding formal logic problems in my dorm’s study room one night when the concept of “axiom” clicked. My whole world shifted. Suddenly, everything made sense—concepts building on each other until you hit foundational ideas you just accept as true. This was my Move 37 moment, and it transformed how I approach conversations. Now, I dig for axioms to dissect others’ reasoning chains.
Idea 5: Is Chinese a Better Tool for Reasoning
ChatGPT and DeepSeek both have faced the “problem” of language mixing so when the model is thinking it often uses Chinese. Now the idea is that when you're talking to someone it is important for you to speak in the language that you understand but it is not necessary for you to think in the language that they understand.

Think of language as a tool for thinking. Personally, I don't think it's an issue because the language you think in isn't important. What matters is thinking correctly and avoiding logical fallacies.
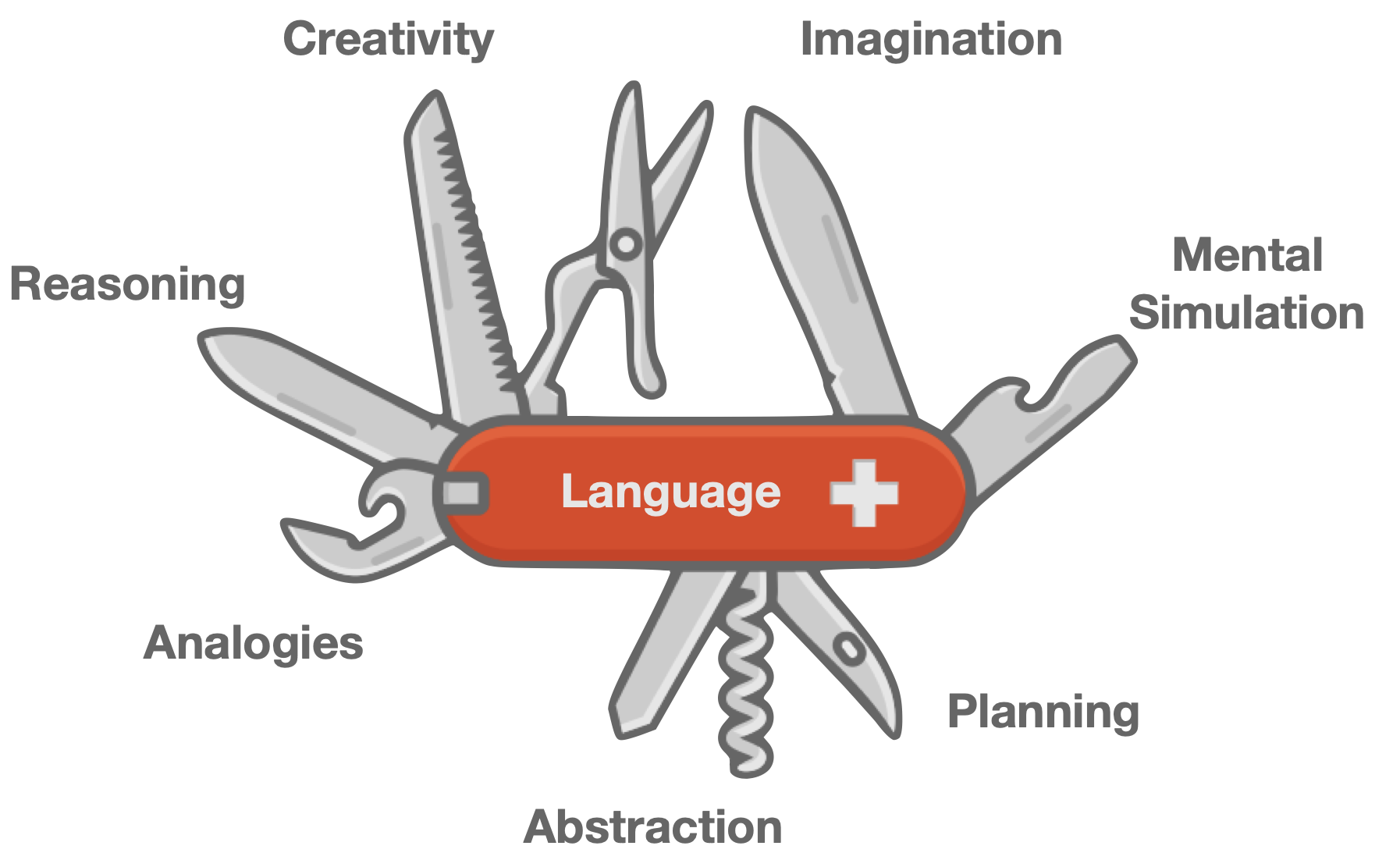
It might be the case that some languages might be better tools for thinking than others. Now let's put on our tinfoil hats for I am about to go on a speculative journey.

A BBC article from 2003 states that “people who speak Mandarin Chinese use both sides of their brain to understand the language compared to English speakers who only need to use one side of their brain”
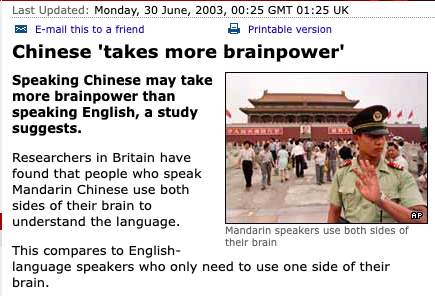
To find out if Chinese is truly a better language for thinking I wondered what is the average IQ of China and it turns out it is 105 which is one the highest in the world
So perhaps it is time for me to switch English for Chinese as my “thinking tool”
Conclusion
I know these ideas are not directly tied to the DeepSeek paper’s technicalities, but these ideas are a testimony to how learning about one thing can lead us to unlock new ideas in a different domain.
This is why I believe it is extremely important that just like LLM’s us humans gather a lot of data and in doing so we can learn a lot of interesting things. Travel, read books, watch movies, go out and talk to strangers, try new cuisines, maybe learn a new language, delve into philosophy.
Another conclusion is that, AI, at least for me, is slowly becoming the lens through which I view ourselves.
- RL taught me that I’m an agent that senses the world and produces actions, and that I have a reward system (pleasure vs. pain) that really guides my actions through life.
- RL in LLMs taught me about how chains of thought emerge from tackling problems repeatedly.
- By seeing how LLMs often fail when they don’t have full context, I’ve realized that I mustn’t expect humans to answer to the best of their ability if they don’t fully have the context.
- The concept of generalizing to unseen data shows me how we humans perform in situations we’ve never encountered—but have been in similar ones before.
- The difficulty in teaching AI sensorimotor and perception skills—vs. the ease of teaching higher-level thinking—shows that walking, traversing the world, seeing, etc., feel effortless. But we really do be making it look easy 😎, and should appreciate our own awesomeness more.
- Overfitting in my own behavior: I learned to type fast on 10FastFingers, but its limited vocabulary haunts me. Sometimes I accidentally type words from its dataset (night) instead of what I meant (naught).
But overall, the point is:
AI helps us learn about ourselves.